
The water consumption prediction has an important place within the water economy. For example, Alicante water utility, in order to be able to distribute potable water to its residents, needs to fill its water tanks. Due to lower energy prices, Alicante water utility is refilling their water tanks over the night – every night. In order to prevent bacteria development in potable water, water needs to be consumed – or disposed (a loss). At the same time, if they run out of water during the day, water utility needs to refill the tanks with energy is in high tariff.
In other words: water consumption prediction is directly related to possible financial losses.
The problem of predicting water consumption, based on historic consumption data, is a classical machine learning problem, and has been assigned to E3, AI department of the JSI (Jožef Stefan Institute).
The results of water consumption prediction produced in the NAIADES project are promising. The algorithms, next to historic consumption data, are filled with weather data as well. While past water consumption data tell us about the typical behaviour in relation to water usage, the weather data (e.g. temperature or precipitation) helps us to catch weather-related impact on water consumption.
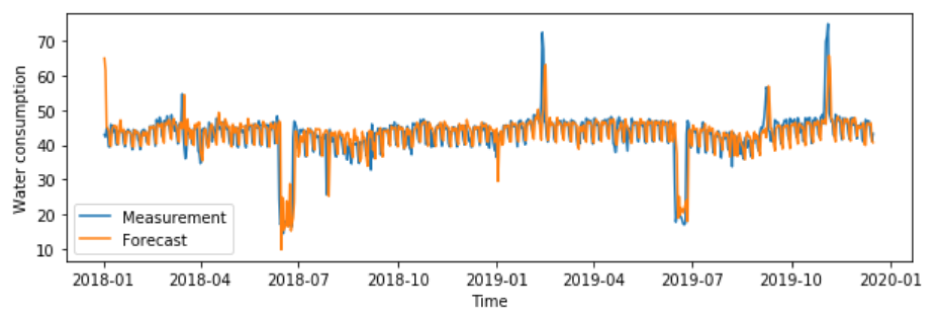
To train algorithms, we have used the most significant aggregates from these two data sets. We created short-term predictions. The figure shows the comparison of the forecasted value (orange) and measured value (blue) of water consumption. As we can see in the figure, predictions are quite accurate (R2 = 0.73).
Our past experiments have, for the moment, pointed out Gradient Boosting Regressor and Random Forest Regressor as the most accurate algorithms for predictions. We are currently experimenting with neural networks, hoping to improve current results.